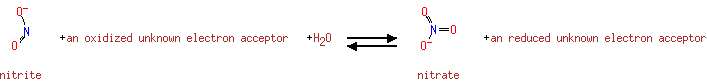| Identification |
| Name: |
Respiratory nitrate reductase 1 alpha chain |
| Synonyms: |
- Nitrate reductase A subunit alpha
- Quinol-nitrate oxidoreductase subunit alpha
|
| Gene Name: |
narG |
| Enzyme Class: |
|
| Biological Properties |
| General Function: |
Involved in oxidoreductase activity |
| Specific Function: |
The nitrate reductase enzyme complex allows E.coli to use nitrate as an electron acceptor during anaerobic growth. The alpha chain is the actual site of nitrate reduction |
| Cellular Location: |
Cell membrane; Peripheral membrane protein |
| KEGG Pathways: |
- Microbial metabolism in diverse environments pae01120
- Nitrogen metabolism pae00910
|
| KEGG Reactions: |
|
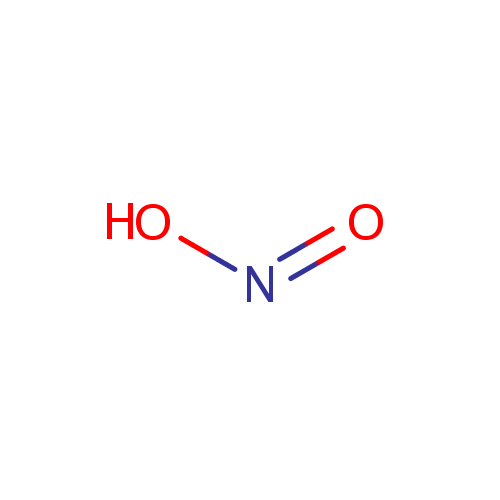
 | + | Acceptor | + | 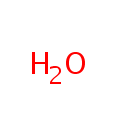 | + | Acceptor | ↔ | 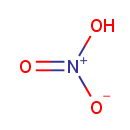 | + | Reduced acceptor | + | Reduced acceptor |
| | |
2 Ferricytochrome c | + | | + | | ↔ | | + | 2 Ferrocytochrome c | + | 2  |
| |
|
| SMPDB Reactions: |
|
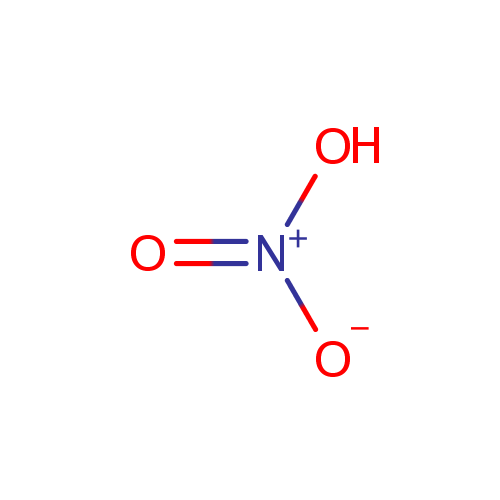
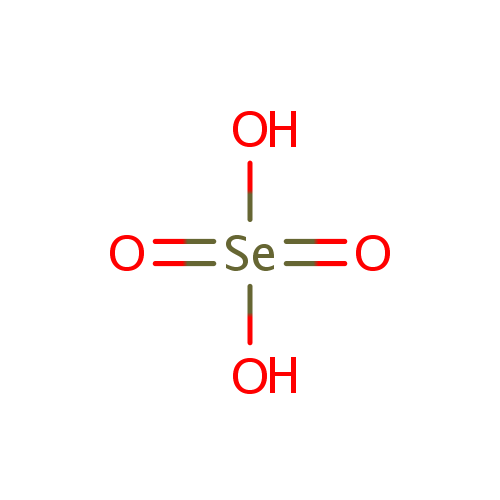
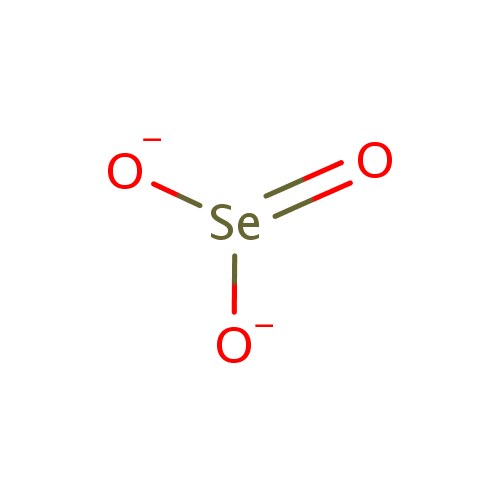
Nitrate | + | cytochrome c nitrite reductase | + | | ↔ | Nitrite | + | cytochrome c nitrite reductase | + | | + | |
| | | | |
| + | 2 | + | "a menaquinol" | → | | + | | + | "a menaquinone" |
| |
|
| PseudoCyc/BioCyc Reactions: |
|
| Complex Reactions: |
| | | | |
| + | acceptor | → | | + | reduced acceptor |
| |
|
| Transports: |
Not Available |
| Metabolites: |
|
| GO Classification: |
| Component |
|---|
| macromolecular complex | | nitrate reductase complex | | protein complex | | Function |
|---|
| binding | | catalytic activity | | cation binding | | electron carrier activity | | ion binding | | metal ion binding | | molybdenum ion binding | | nitrate reductase activity | | oxidoreductase activity | | oxidoreductase activity, acting on other nitrogenous compounds as donors | | transition metal ion binding | | Process |
|---|
| metabolic process | | nitrate metabolic process | | nitrogen compound metabolic process | | oxidation reduction |
|
| Gene Properties |
| Locus tag: |
PA3875 |
| Strand: |
- |
| Entrez Gene ID: |
879780 |
| Accession: |
NP_252564.1 |
| GI: |
15599070 |
| Sequence start: |
4338261 |
| Sequence End: |
4342046 |
| Sequence Length: |
3785 |
| Gene Sequence: |
>PA3875
ATGAGTCACCTGCTCGACCGCCTGCAGTTCTTCAAGAAGAAGCAGGGCGAATTCGCCGATGGCCACGGCGAGACCAGCAACGAGAGCCGCGCCTGGGAAGGTGCCTACCGGCAGCGCTGGCAGCACGACAAGATCGTGCGCTCCACCCACGGGGTGAACTGCACCGGCTCCTGCTCCTGGAAGATCTACGTGAAGAACGGCCTGATCACCTGGGAAACCCAGCAGACCGACTACCCGCGCACCCGTCCGGACCTGCCCAACCACGAGCCGCGCGGCTGCCCGCGCGGGGCCAGCTATTCCTGGTACATCTACAGCGCCAACCGCCTGAAGTACCCGAAGGTGCGCAAGCCGTTGCTCAAGCTCTGGCGCGAGGCGCGGGCGCAGCACGGCGACCCGGTGAACGCCTGGGCCAGCATCGTCGAGGACGCCGCCAAGGCGAAGAGCTACAAGAGCCAGCGCGGCCTGGGTGGCTTCGTCCGTTCCAGCTGGGACGAGGTCACCGAGATCATCGCCGCGGCCAACGTCTACACCGCCAAGACCTACGGTCCGGACCGGGTGATCGGCTTCTCGCCGATCCCGGCCATGTCGATGGTCAGCTACGCCGCCGGCGCCCGCTACCTGTCGCTGATCGGCGGGGTCTGCCTGAGCTTCTACGACTGGTACTGCGACCTGCCGCCGGCCAGCCCGCAGATCTGGGGCGAGCAGACCGACGTGCCGGAGTCGGCCGACTGGTACAACTCCAGCTACATCATCGCCTGGGGCTCCAACGTGCCGCAGACGCGGACCCCGGACGCGCACTTCTTCACCGAGGTGCGCTACAAGGGCACCAAGACCGTCTCCATCACCCCGGACTATTCCGAGGTGGCCAAGCTCACCGACCTCTGGCTCAACCCCAAGCAGGGCACCGACGCCGCGCTGGGCATGGCCTTCGGTCACGTGATCCTGAAGGAGTTCCACCTCGACCGGCCGAGCGCCTACTTCGTCGACTACTGCCGCCAGTACACCGACATGCCGATGCTGGTGTTGCTGGAAGAACACGCCGGCGGCGCGTTCAAGCCGACCCGCTACCTGCGCGCCGCCGACCTGGCGGACAACCTCGGCCAGGACAACAACCCCGAGTGGAAGACCATCGCCTACGACGAGCGCAGCGGCGGGCTGGTCTCGCCCACCGGCGCCATCGGCTACCGCTGGGGCGAGTCTGGCAAGTGGAACATCGCCGAGCTGGACGGCAGGAGCGGTGACCAGACGCGCCTGCAACTGTCGCTGCTCGATGGCCCGGAACATGCCTGCGAGGTGGCCTTCCCGTACTTCGCCGGGCAGGAGCACCCGCACTTCAAGGGCGTCGCCAACGACGAGGTACTGCTGCGCCGGGTGCCGTTCCGCGAGATCGTCGCGGCGGACGGCAAGCGCCTGCGGGTGGCCACCGTCTATGACCTGCAGATGGCCAACTACAGCATCGACCGCGGCCTGGGCGGCGACAACGTGGCGACCTCCTACGAGGACGCCGACACGCCCTATACCCCGGCCTGGCAGGAGCGCATCACCGGCGTCCCGGCGGCGCGCGCGACGCAGGTCGCCCGCGAGTTCGCCGACAGCGCCGACAAGACCCGCGGCAAGGCGATGGTGATCATCGGCGCGGCGATGAACCACTGGTACCACATGGACATGAACTACCGCGCGGTCATCAACATGCTGATGATGTGCGGCTGCATCGGCCAAAGCGGCGGCGGCTGGGCGCACTATGTCGGCCAGGAGAAGCTGCGCCCGCAGACCGGCTGGGCGCCGCTGGCCTTCGGCCTGGACTGGAGCCGGCCGCCGCGGCAGATGAACGGCACCAGCTTCTTCTACCTGCACAGCTCGCAATGGCGCCACGAGAAGCTGTCGATGCACGAGGTGCTGTCGCCGCTGGCCGACGCCAGCCGCTTCGCCGAACACGCCCTGGACTACAACATCCAGGCCGAACGCCTCGGCTGGCTGCCGTCGGCGCCGCAACTGAACCGCAACCCGCTGCGCATCGCCGCCGAGGCCGAGGCCGCCGGCCTGCCGGTCGCCGACTATGTGGTGCGTGAACTGAAGAGCGGCGGCCTGCGCTTCGCCAGCGAATCGCCGGACGATCCGCAGAACTTCCCGCGCAACATGTTCATCTGGCGCTCCAACCTGCTGGGCTCCTCCGGCAAGGGGCACGAGTACATGCTCAAGTACCTGCTCGGGGCGAAGAACGGGGTGATGAACGATGACCTCGGCAAGGCCGGCGGTCCGCGTCCCACCGAGGTCGACTGGGTCGACGACGGTGCCGAGGGCAAGCTCGACCTGGTCACCACCCTGGACTTCCGCATGTCCTCCACCTGCATGTACTCGGACATCGTCCTGCCGACCGCTACCTGGTACGAGAAGGACGACCTCAACACCTCCGACATGCACCCCTTCATCCATCCGCTGTCGGCGGCCACCGATCCGGCCTGGGAAGCCAAGAGCGACTGGGAGATCTACAAGGCCATCGCCAAGAAGTTCTCCGCCGTCGCCGAAGGCCACCTCGGCGTGGAGCAGGACCTGGTCACGGTGCCGCTGCTGCATGACACCCCCACCGAGCTGGCGCAGCCGTTCGGCGGCGACGGCCATGACTGGAAGAAGGGCGAGTGCGAGCCGGTGCCGGGACGCAACCTGCCGACGCTGCACCTGGTCGAGCGCGACTACCCGAACGTCTACCGCAAGTTCACCTCGCTCGGTCCGCTGCTGGACAAGCTGGGCAACGGCGGCAAGGGCATCGGCTGGAACACCGAGAAGGAAGTGAAGCTGGTCGGCGACCTCAACCATCGCGTGGTCGAGAGCGGCGTCAGCCAGGGCCGGCCGCGTATCGACAGCGCCATCGACGCCGCCGAGGTGGTCCTCGCCCTGGCTCCGGAAACCAACGGCCAGGTCGCGGTCAAGGCCTGGGAAGCGCTGTCGAAGATCACCGGCCGCGAGCACGCCCACCTGGCGCTGCCCAAGGAAGACGAGAAGATCCGCTTCCGCGACATCCAGGTGCAGCCGCGCAAGATCATCTCCAGCCCGACCTGGTCCGGCCTCGAGGACGAGCACGTCAGCTACAACGCCGGCTACACCAACGTCCACGAGCTGATCCCGTGGCGCACCATCACCGGTCGCCAGCAGTTCTACCAGGACCACCCGTGGATGCAGGCGTTCGGCGAAGGCTTCGTCAGCTACCGGCCGCCGGTCAACACCCGGACCACCGAGAAACTGTTGAACAGGAAGCCCAACGGCAACCCGGAGATCACCCTGAACTGGATCACCCCGCACCAGAAATGGGGCATCCACTCCACCTACAGCGACAACCTGCTGATGCTCACCCTGTCGCGCGGCGGTCCGATCATCTGGCTCAGCGAGCACGACGCGGCCAAGGCCGGGATCGTCGATAACGACTGGGTCGAGGTGTTCAACGCCAACGGCGCGGCGACCTGCCGCGCGGTGGTCAGCCAGCGGGTCAAGGACGGCATGGTGATGATGTACCACGCCCAGGAACGCATCGTGAACGTACCCGGCAGCGAGACCACCGGCACCCGTGGCGGCCACCACAACTCGGTGACCCGCGTGGTGCTCAAGCCGACCCACATGATCGGCGGCTACGCCCAGCAGGCCTGGGGCTTCAACTACTACGGCACGGTCGGCTGCAACCGCGACGAGTTCGTCGTGGTGCGCAAGATGAGCAAGGTCGACTGGCTGGACGAACCCCGCCACGGCGGACTCGGCGGCGACGCCCTGCCGCAACCGCTGCCCCAGGACATTTGA |
| Protein Properties |
| Protein Residues: |
1261 |
| Protein Molecular Weight: |
141 kDa |
| Protein Theoretical pI: |
6.74 |
| Hydropathicity (GRAVY score): |
-0.482 |
| Charge at pH 7 (predicted): |
-5.47 |
| Protein Sequence: |
>PA3875
MSHLLDRLQFFKKKQGEFADGHGETSNESRAWEGAYRQRWQHDKIVRSTHGVNCTGSCSWKIYVKNGLITWETQQTDYPRTRPDLPNHEPRGCPRGASYSWYIYSANRLKYPKVRKPLLKLWREARAQHGDPVNAWASIVEDAAKAKSYKSQRGLGGFVRSSWDEVTEIIAAANVYTAKTYGPDRVIGFSPIPAMSMVSYAAGARYLSLIGGVCLSFYDWYCDLPPASPQIWGEQTDVPESADWYNSSYIIAWGSNVPQTRTPDAHFFTEVRYKGTKTVSITPDYSEVAKLTDLWLNPKQGTDAALGMAFGHVILKEFHLDRPSAYFVDYCRQYTDMPMLVLLEEHAGGAFKPTRYLRAADLADNLGQDNNPEWKTIAYDERSGGLVSPTGAIGYRWGESGKWNIAELDGRSGDQTRLQLSLLDGPEHACEVAFPYFAGQEHPHFKGVANDEVLLRRVPFREIVAADGKRLRVATVYDLQMANYSIDRGLGGDNVATSYEDADTPYTPAWQERITGVPAARATQVAREFADSADKTRGKAMVIIGAAMNHWYHMDMNYRAVINMLMMCGCIGQSGGGWAHYVGQEKLRPQTGWAPLAFGLDWSRPPRQMNGTSFFYLHSSQWRHEKLSMHEVLSPLADASRFAEHALDYNIQAERLGWLPSAPQLNRNPLRIAAEAEAAGLPVADYVVRELKSGGLRFASESPDDPQNFPRNMFIWRSNLLGSSGKGHEYMLKYLLGAKNGVMNDDLGKAGGPRPTEVDWVDDGAEGKLDLVTTLDFRMSSTCMYSDIVLPTATWYEKDDLNTSDMHPFIHPLSAATDPAWEAKSDWEIYKAIAKKFSAVAEGHLGVEQDLVTVPLLHDTPTELAQPFGGDGHDWKKGECEPVPGRNLPTLHLVERDYPNVYRKFTSLGPLLDKLGNGGKGIGWNTEKEVKLVGDLNHRVVESGVSQGRPRIDSAIDAAEVVLALAPETNGQVAVKAWEALSKITGREHAHLALPKEDEKIRFRDIQVQPRKIISSPTWSGLEDEHVSYNAGYTNVHELIPWRTITGRQQFYQDHPWMQAFGEGFVSYRPPVNTRTTEKLLNRKPNGNPEITLNWITPHQKWGIHSTYSDNLLMLTLSRGGPIIWLSEHDAAKAGIVDNDWVEVFNANGAATCRAVVSQRVKDGMVMMYHAQERIVNVPGSETTGTRGGHHNSVTRVVLKPTHMIGGYAQQAWGFNYYGTVGCNRDEFVVVRKMSKVDWLDEPRHGGLGGDALPQPLPQDI |
| References |
| External Links: |
|
| General Reference: |
PaperBLAST - Find papers about PA3875 and its homologs
|